NAVER API를 사용해서 크롤링하기 - 2
in Development on Crawling
이전 포스팅에서 네이버 API를 신청하고, 내 애플리케이션까지 등록해서 API를 사용할 때 필요한 Client ID와 Secret을 모두 발급을 받았다. 그리고 API Documents에서 검색 API에 관한 내용을 찾아서 아래의 Python 예제 코드까지 확인했는데 코드를 확인해보자.
import os
import sys
import urllib.request
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
encText = urllib.parse.quote("검색할 단어")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
내 애플리케이션 인증
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
우선 이 부분은 내가 네이버 API를 사용하기 전에 나라는 걸 인증하는 인증키와 키를 입력하는 부분이다. 이전 포스팅에서 내 애플리케이션에서 발급받은 Client ID와 Client Secret을 여기에 입력하면 된다.
검색 키워드 Parsing
encText = urllib.parse.quote("검색할 단어")
네이버 뉴스, 쇼핑, 블로그 등에서 특정한 글을 찾고 싶을 때 검색할 단어를 입력한다. 크롤링을 할 때도 어떤 단어를 기반으로 검색할 것인지 검색할 단어를 입력한다. 하지만, 내가 검색할 단어에 특수문자가 포함 되어있으면 특수문자 그대로 전달을 할 수 없다. 한글도 특수문자에 해당한다. 따라서 인코딩 작업이 필요한데 quote 함수가 인코딩 작업을 해준다. “코로나”를 인코딩하면 다음과 같이 나온다.
import urllib
Encoding_word = urllib.parse.quote("코로나")
print (Encoding_word)
'%EC%BD%94%EB%A1%9C%EB%82%98'
요청 URL
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
검색할 단어까지 확인됐으면, 단어를 매개변수로 포함해서 요청할 URL 주소가 완성된다. 요청한 URL에 대한 응답 결과를 받을 때 2가지 방식의 출력 포맷으로 제공해준다. 아래 그림에서 보는 것처럼 XML과 JSON 형태로 제공된다.
 default로 JSON 출력 포맷의 결과를 제공해주는데 XML 결과로 받고 싶으면 blog.xml로 요청해주면 된다.
default로 JSON 출력 포맷의 결과를 제공해주는데 XML 결과로 받고 싶으면 blog.xml로 요청해주면 된다.
요청 & 응답
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request) ##요청 & 응답
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
Naver 블로그 서버에 요청할 객체를 생성하고, 나를 인증하는 id와 secret 정보를 헤더에 포함해서 요청을 한다. 요청 처리에 대한 응답을 response에 저장하고 getcode() 함수로 상태 코드를 알아낸다. 웹 페이지가 제대로 요청이 되었으면 일반적으로 HTTP 코드 200을 반환한다. 응답 코드가 200이면 read() 함수로 데이터를 읽어서 출력해서 확인하면 된다. 응답한 내용은 바이트 타입이므로 UTF-8 디코딩을 통해 문자열로 변경한다.
“코로나”라는 단어로 검색한 결과를 확인하면 다음과 같다. 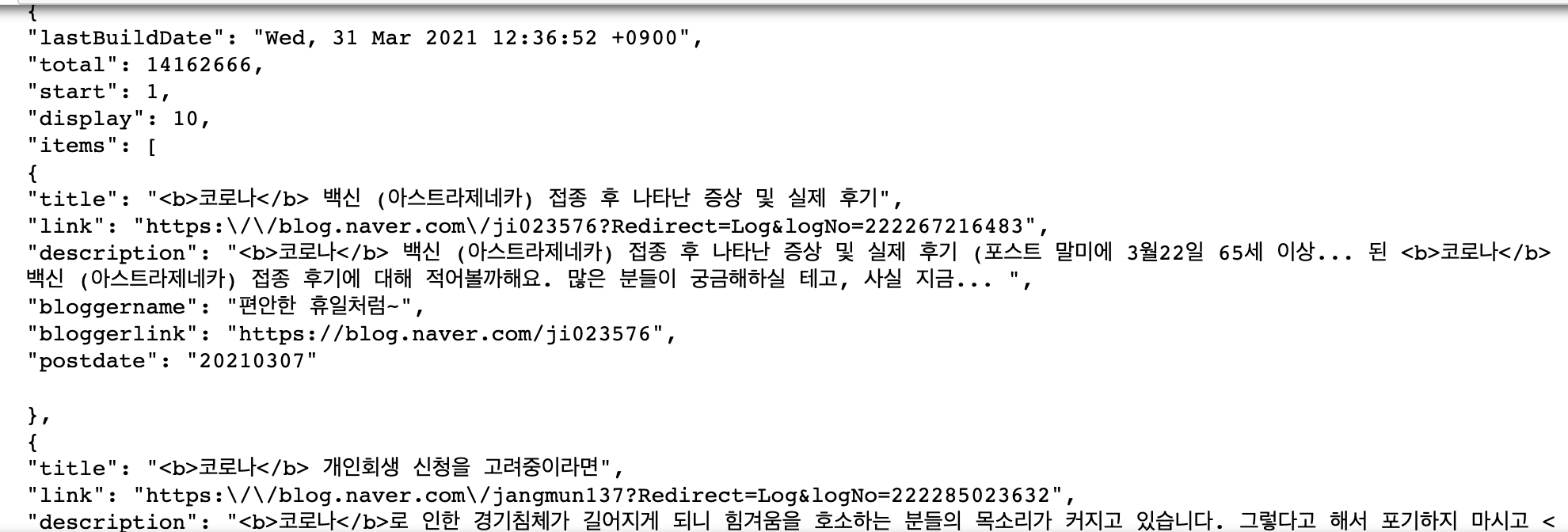
출력된 결과가 의미하는 것들은 출력 결과 설명 부분을 확인하면 알 수 있다. 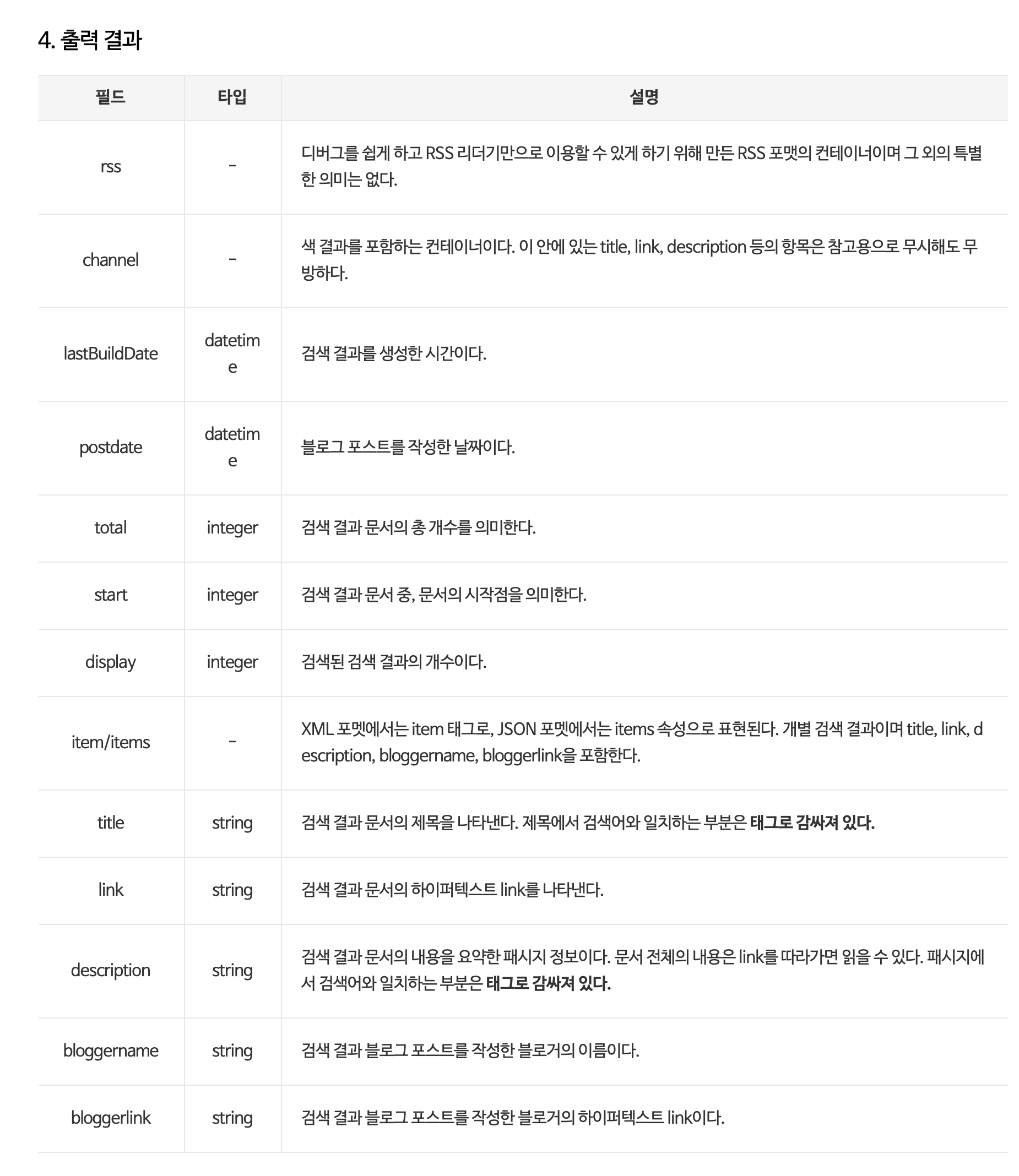
API를 사용해서 받은 블로그 검색 결과와 네이버 블로그 홈페이지에서 코로나를 직접 입력해서 나온 결과를 비교해보면 첫 번째 글의 제목이 “코로나 백신 (아스트라제네카)…” 로 같은 것을 확인할 수 있다. 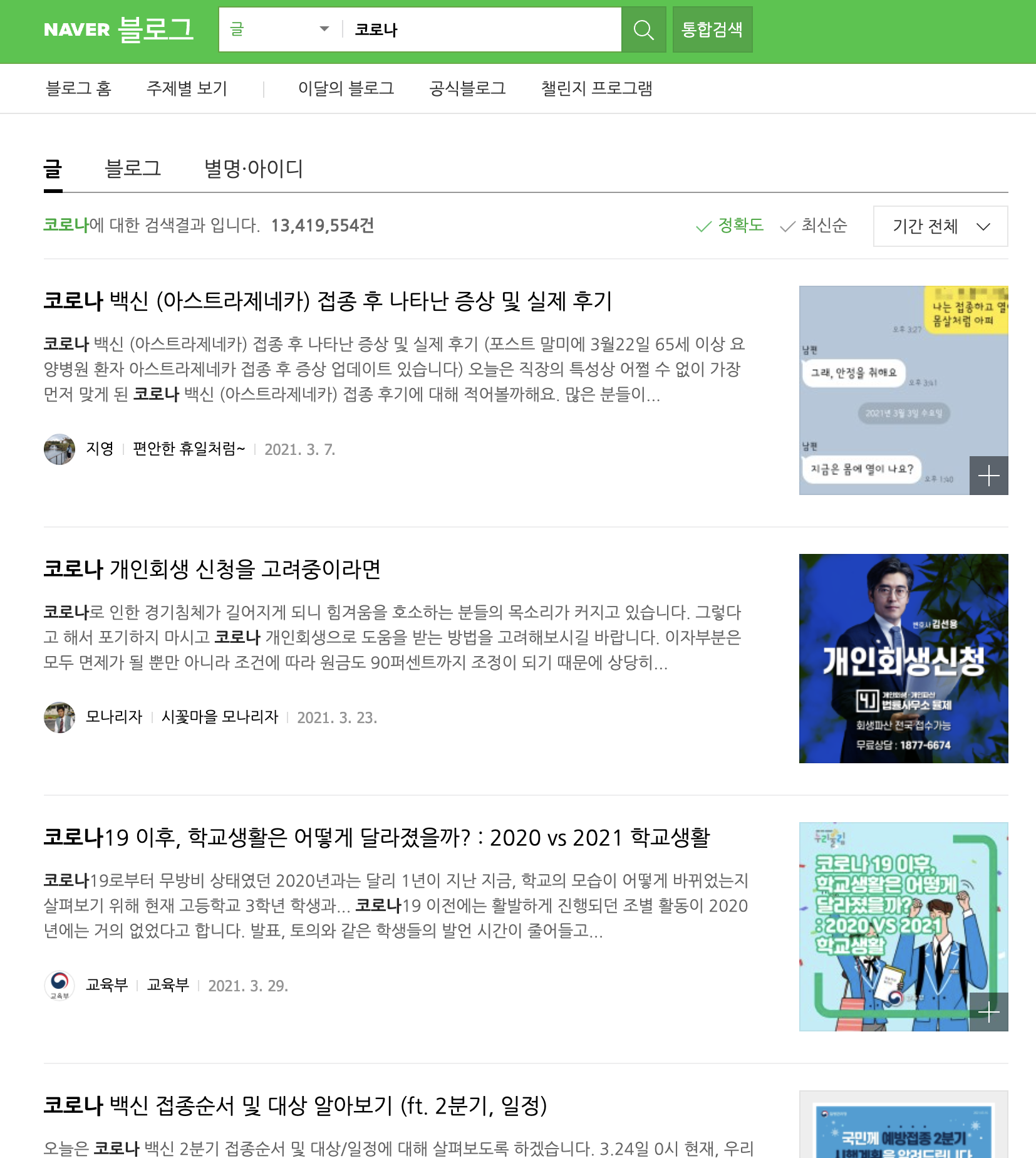
혹시라도 요청이 부적절하거나 오타가 나는 등의 이유로 요청이 이루어지지 않은 경우 에러코드를 출력하는데 다음과 같은 에러들이 있다.
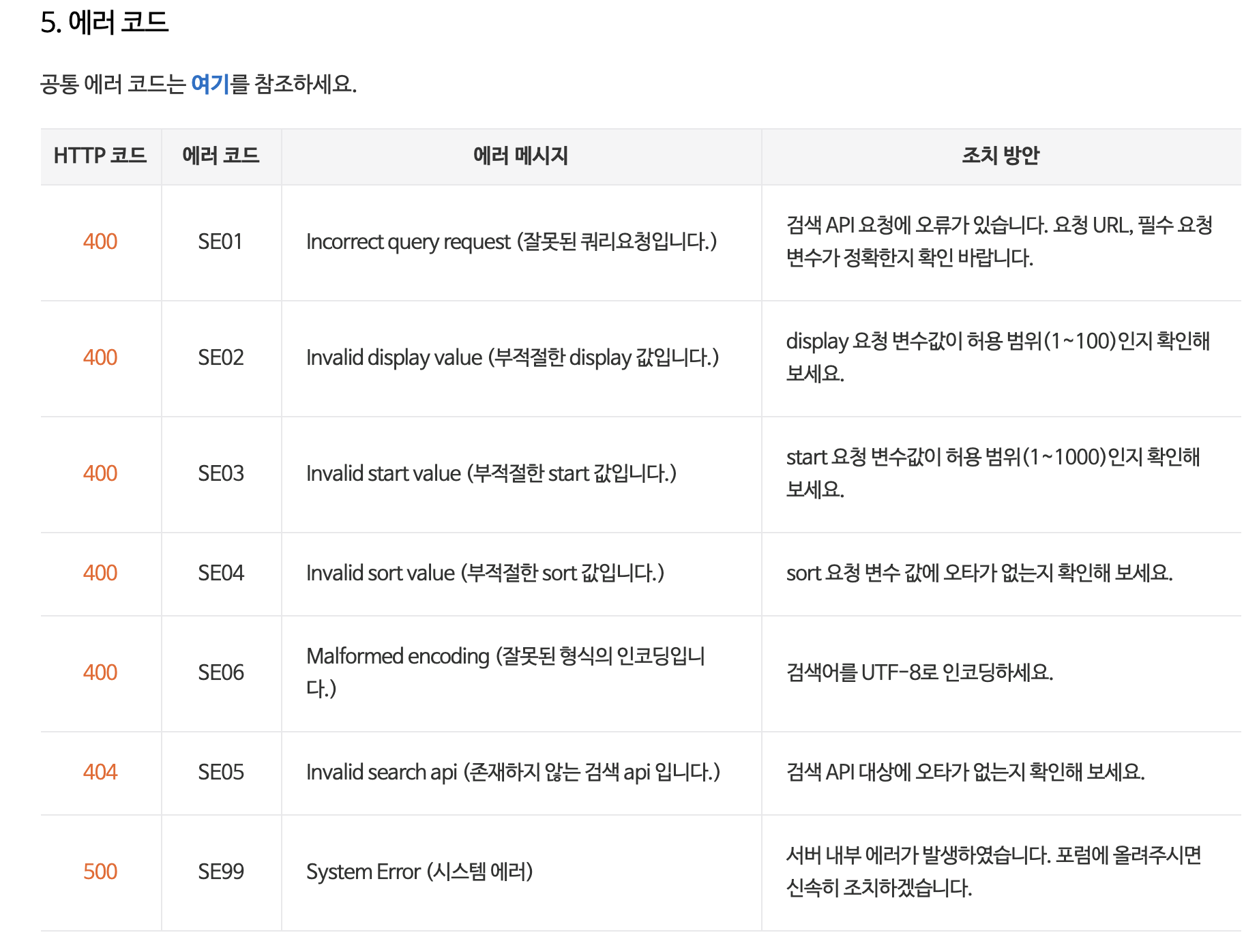
요청 변수
위에 “코로나” 블로그 검색 결과를 살펴보면 결과 Key 값들 중에 start, display를 확인할 수 있다. start는 검색 시작 위치를 몇 번째 글부터 시작할지, display는 총 몇 개의 글을 출력할 것인지 건수를 정하는 변수다. 내가 처음에 요청한 결과는 URL에서 필수 변수에 해당하는 검색 단어 query만 입력했다. query 이외에도 display, start와 유사도 또는 날짜순으로 정렬을 할 수 있는 sort 옵션까지 요청 변수를 추가할 수 있다. 요청 변수는 다음과 같다.
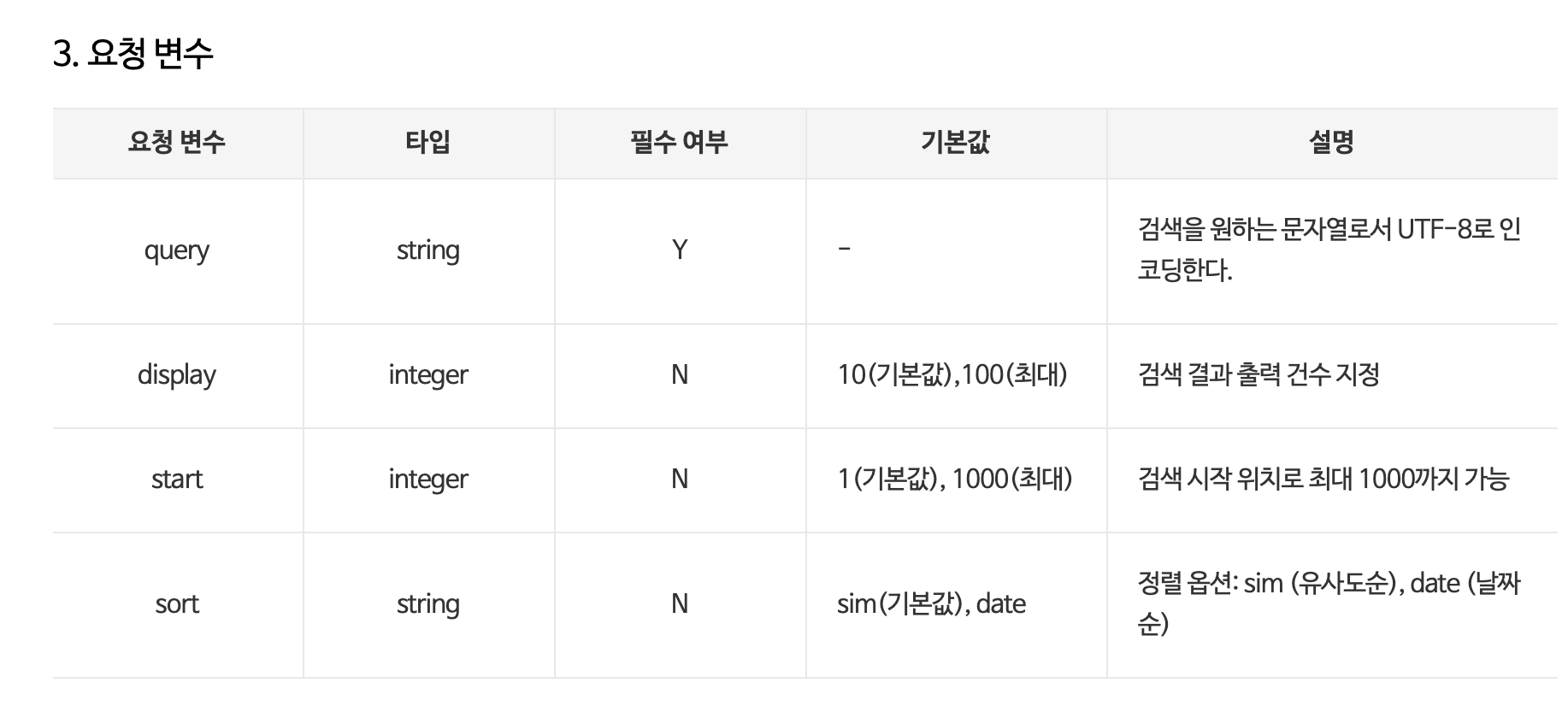
요청 변수를 모두 사용해서 요청하는 예제는 다음과 같다.
curl "https://openapi.naver.com/v1/search/blog.xml?query=%EB%A6%AC%EB%B7%B0&display=10&start=1&sort=sim" \
-H "X-Naver-Client-Id: {애플리케이션 등록 시 발급받은 client id 값}" \
-H "X-Naver-Client-Secret: {애플리케이션 등록 시 발급받은 client secret 값}" -v
query가 무엇인지 확인하기 위해서 quote parsing을 반대로 진행한다.
urllib.parse.unquote("%EB%A6%AC%EB%B7%B0")
"리뷰"
검색할 단어는 리뷰이며, 검색할 건수는 10건이며, 시작은 첫 번째 글부터 시작하며, 유사도 정렬 순으로 출력을 했다. 만약 시작을 15번째 글부터 시작해서 100건을 날짜순으로 출력하고 싶으면 다음과 같이 요청 URL을 사용하면 된다.
url = "https://openapi.naver.com/v1/search/blog.xml?query=%EB%A6%AC%EB%B7%B0&display=100&start=15&sort=date"
또한, 블로그가 아니라 뉴스, 카페, 영화, 쇼핑 등 다른 카테고리의 검색 결과를 요청하고 싶으면 “blog”를 “news”, “cafearticle”, “movie”, “shop” 으로 변경할 수도 있다. 이는 API 검색 문서에서 다른 카테고리들을 확인해보면 알 수 있다.